update(20210810): 补充了自适应vad参数的相关内容
VAD-Voice Active Detection. 几乎所有的语音任务中,都可以见到VAD的身影。 在编解码问题中,vad可应用于低码率编码静音段数据减少网络数据传输。 在ASR中,vad可以用来定位音频起始时间,大幅度提升系统rtf。 在语音增强中,vad用来获得谱减法需要的时间背景噪声信号。 TTS/VC中,vad同样在数据处理中发挥了重要作用。
DNN-base or 更复杂的vad算法大行其道,数据驱动下,vad可以做更多的事情, 例如区分人声与非人声(SAD/Speech Active Detection)等。 数据驱动方案固然可以得到更好的精度,但也要付出性能和延迟的代价,以及面临目录领域和数据领域匹配的问题。
这篇post会更多讲一下基于信号处理中VAD算法的实现和应用。 例如现代asr系统中,一个合理的选择就是前端的轻量级vad+后端足够鲁棒的asr模型,而不是一个较重的前端降噪系统。
base python implement
完整项目和更多细节可以参考我的github项目
核心算法非常简单,通过计算每个窗口内能量并合阈值进行判断。代码如下:
mse = librosa.feature.rms(y, frame_length=self._frame_length,
hop_length=self._hop_length) ** 2
signal_db = librosa.power_to_db(mse.squeeze(), ref=self._ref, top_db=None)
start, end = None, None
sil_endpoints = []
for x in range(-1, len(signal_db)):
if x not in sil_index and (x + 1) in sil_index:
start = int(librosa.frames_to_samples(x + 1, self._hop_length))
if x in sil_index and x + 1 not in sil_index:
end = int(librosa.frames_to_samples(x, self._hop_length))
sil_endpoints.append((start, end))
sil_endpoints = [(_s, _e) for _s, _e in sil_endpoints if _e - _s > 1]
与此同时,对核心代码进行了上层封装,使之可以支持采样点和mel谱两种输入,同时实现了离线和流式两种封装接口以方便使用。 根据以往的项目经验,提供一些常用的经验参数可供使用。
vad 参数设置和自适应方法
energy-based-vad 算法中,可以看出核心参数就是确认能量阈值。 不同的噪声水平该值可能会对应不同的值,实际使用中,选择合理的取值可能需要花一些时间和心思。
对自动取值进行了一些探索。
webrtcvad 解析
首先,去读了一下 webrtc 中的 vad 算法,其重点就是流式场景下 vad 阈值的自适应, 算法层面有一些精彩的处理,感觉还是很有收获。
总结一些核心要点,当然更多细节尽在 webrtc-vad 源码
- 音频无论输入采样率,都降低到8k采样率,不影响效果
- 使用了子带能量来代替了总能量 (6个不同的子带,80~250,250~500,500~1000,1000~2000,2000~3000,3000~4000)。 考虑到交流电带来50hz的干扰,下限频率设置的不能过低。 对每个子带能量进行判断,如果有一个子带能量超过阈值,则判定为speech。
- 假设了noise和speech都服从正态分布,整个信号能量分布是两个正态分布的叠加。
- 经典的EM算法,更新两个正态分布的均值和方差。 随着时间演进更新迭代参数,意味这参数可以对噪声自适应。
- 采用了假设检验的方法(likelihood ratio test with hypothesis)。
当然还有一些编程技巧和数值计算上的trick,这里就不列出。
gmm-vad 的核心思想和主要优势是针对流式场景不同复杂环境下的自适应参数, 这可能是nn-vad不太好处理的情况。
基于统计的vad参数确认方法
对于离线场景来说,我们不需要考虑那么多。但希望能借鉴自适应参数这个优点。 或者至少可以对批量数据自动生成对应能量阈值。
根据 webrtc-vad 的想法,我们首先看下对噪声水平相近的一批数据,在能量分布上是否满足 混合高斯分布(K=2)的假设。
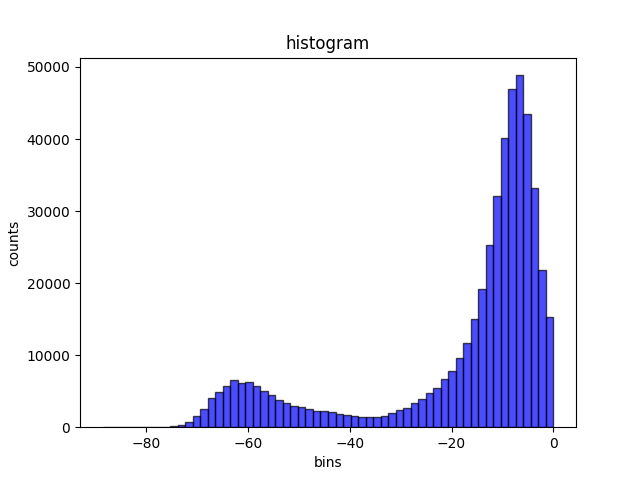
这是某个公开tts数据集(bzn)的分布,相对比较干净
某个实际业务数据集(代号lx)的分布,噪声相对比较多
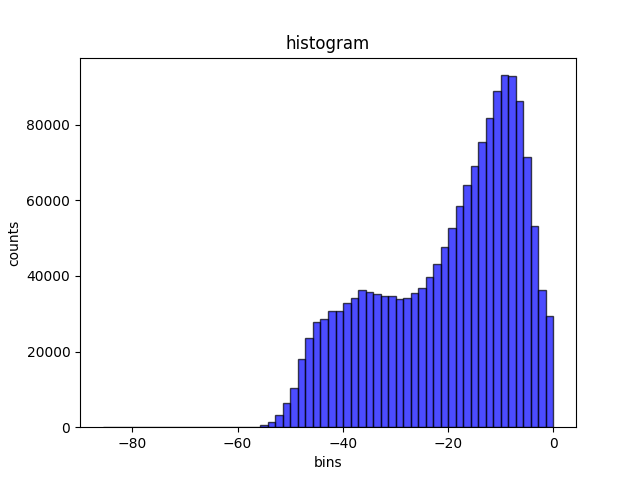
很容易看出,混合高斯模型假设基本成立,可以看到明显的两个峰值。肉眼即可大致看出两个分布的均值。 同时,两个数据集的分布有明显的差异,对于干净数据集,两个正态分布重叠部分较小。
(这似乎是一个有效的判断数据集噪声水平的方法?)
solve mixed-GMM
使用EM算法求解混合高斯模型。
import numpy as np
def Normal(x, mu, sigma): # 一元正态分布概率密度函数
return np.exp(-(x - mu) ** 2 / (2 * sigma ** 2)) / (
np.sqrt(2 * np.pi) * sigma)
N = np.size(data)
Mu = np.array([[-60.0, -10]])
SigmaSquare = np.array([[100, 100]])
Alpha = np.array([[0.5, 0.5]])
for i in range(1000):
# Expectation
gauss1 = Normal(data, Mu[0][0], np.sqrt(SigmaSquare[0][0]))
gauss2 = Normal(data, Mu[0][1], np.sqrt(SigmaSquare[0][1]))
Gamma1 = Alpha[0][0] * gauss1
Gamma2 = Alpha[0][1] * gauss2
M = Gamma1 + Gamma2
# Maximization, update SigmaSquare, mu and alpha
SigmaSquare[0][0] = np.dot((Gamma1 / M).T, (data - Mu[0][0]) ** 2) / np.sum(
Gamma1 / M)
SigmaSquare[0][1] = np.dot((Gamma2 / M).T, (data - Mu[0][1]) ** 2) / np.sum(
Gamma2 / M)
Mu[0][0] = np.dot((Gamma1 / M).T, data) / np.sum(Gamma1 / M)
Mu[0][1] = np.dot((Gamma2 / M).T, data) / np.sum(Gamma2 / M)
Alpha[0][0] = np.sum(Gamma1 / M) / N
Alpha[0][1] = np.sum(Gamma2 / M) / N
if i % 10 == 0:
print("第", i, "次迭代:")
print("Mu:", Mu)
print("Sigma:", np.sqrt(SigmaSquare))
print("Alpha", Alpha)
假设检验
在 webrtc 代码中,使用假设检验来判断。假设检验的判断公式如下:
log_likelihood_ratio = log2(Pr{X|H1} / Pr{X|H0})
求得混合高斯腹部的 mu 和 sigma 后,很容易求得对应的 log_likelihood_ratio
对于不同的mode,使用不同的llr阈值即可。(即代码中的kLocalThresholdQ)
// Constants used in WebRtcVad_set_mode_core().
//
// Thresholds for different frame lengths (10 ms, 20 ms and 30 ms).
//
// Mode 0, Quality.
static const int16_t kOverHangMax1Q[3] = { 8, 4, 3 };
static const int16_t kOverHangMax2Q[3] = { 14, 7, 5 };
static const int16_t kLocalThresholdQ[3] = { 24, 21, 24 };
static const int16_t kGlobalThresholdQ[3] = { 57, 48, 57 };
// Mode 1, Low bitrate.
static const int16_t kOverHangMax1LBR[3] = { 8, 4, 3 };
static const int16_t kOverHangMax2LBR[3] = { 14, 7, 5 };
static const int16_t kLocalThresholdLBR[3] = { 37, 32, 37 };
static const int16_t kGlobalThresholdLBR[3] = { 100, 80, 100 };
// Mode 2, Aggressive.
static const int16_t kOverHangMax1AGG[3] = { 6, 3, 2 };
static const int16_t kOverHangMax2AGG[3] = { 9, 5, 3 };
static const int16_t kLocalThresholdAGG[3] = { 82, 78, 82 };
static const int16_t kGlobalThresholdAGG[3] = { 285, 260, 285 };
// Mode 3, Very aggressive.
static const int16_t kOverHangMax1VAG[3] = { 6, 3, 2 };
static const int16_t kOverHangMax2VAG[3] = { 9, 5, 3 };
static const int16_t kLocalThresholdVAG[3] = { 94, 94, 94 };
static const int16_t kGlobalThresholdVAG[3] = { 1100, 1050, 1100 };
可以通过此方法,反推求出 signal-energy-based threshold
实际中,也可以粗略得,直接从 hist 直方图中,找到两个正太分布的交点 (两个尖峰中间波谷的最低点)作为 threshold
application 基本应用场景
offlineVAD and onlineVAD
- offlineVAD 使用单条音频的最大能量作为基准值,onlineVAD 人为给定全局能量基准值。
- 可以通过tools.feature_and_signal.tool_vad中的方法获得全局能量基准值。
- 一般来说,offlineVAD 更为精确,但两者差别不大。
vad for tts(tacotron)
基于 attention 的 tts 声学模型(e.g. Tacotron),如果训练数据中, 句首和句末包括了过长的静音,可能会存在对齐无法收敛和解码停不下来的情况。 因此,librosa.trim_silence 是很多实现中多会采用的 trick。 如果是自己采集的数据,句中的过长静音也同样是需要考虑的问题。
vad for vocoder
- 截取训练数据中过多的静音段,避免标签的不平衡(静音段占比过大),提高模型鲁棒性。 特别是针对 wrnn 等自回归类声码器(wrnn)。
- vad获得背景杂音,使用谱减法对音频进行降噪。(和解码中先生成静音bias,再用实际生成语音减掉bias类似。)
- 推理过程中使用基于频谱的vad算法,提高推理速度。特别是在流式场景下,省掉首片解码中的静音段可以大幅降低开销。
- 在自回归类声码器中(wrnn),根据vad结果,重置gru/lstm的memory,缓解解码阶段超长音频带来的影响。
vad for vc
与asr类似,使用 vad 对输入音频进行预处理。vad切分,可以避免过长的音频,减轻转换模型的负担。 同时,使用 vad 过滤掉静音段(以及含有微小噪声的非语音段),可以达到降噪并提高 rtf 的效果。一举两得。